Infrastruktur / KI-Werkbank
Im Zuge der inhaltlichen Arbeit im Rahmen der einzelnen Projekte in Unternehmen hat sich bereits früh abgezeichnet, dass die lokale Installation der benötigten Softwarekomponenten beispielsweise auf Notebooks wenig zielführend ist. All-In-One Lösungen wie Rapidminer bieten zwar einen schnellen Einstieg in das Themenfeld, kommen allerdings bei der Generierung neuer Datensatzeigenschaften (“Features”) schnell an ihre Grenzen. Für unternehmensspezifische Problemstellungen, wie sie in der KI-Werkstatt behandelt wurden, muss entsprechend auf die Umsetzung mittels Programmiersprache zurückgegriffen werden. In der KI-Werkstatt wurde primär mit der Programmiersprache Python und den Bibliotheken “pandas” sowie “scikit learn” gearbeitet. Die lokale Installation der benötigten Komponenten auf einem Desktoprechner ist grundsätzlich möglich und funktioniert, birgt aber folgende Nachteile:
- Das KI-Projekt liegt lokal ab und kann entsprechend nur von einer Person zur Zeit betreut werden
- Die Rechenleistung eines einzelnen Desktops ist in der Regel stark begrenzt
- Die Kompatibilität der einzelnen Bibliotheken untereinander muss vom Anwender sichergestellt werden. Wird eine Bibliothek, zum Beispiel wegen einer neuen Funktion, aktualisiert, sollten auch alle weiteren verwendeten Bibliotheken aktualisiert werden.
Wie bereits im Bereich Getting Started angeführt, bietet die Plattform “Kaggle” Nutzer*innen die Möglichkeit, mittels eines Webbrowsers Pythonscripte zu erstellen. Hintergrund ist hier, dass Nutzer*innen über ihren Webbrowser lediglich Zugriff auf den Python-Code an sich haben. Die Webumgebung hierfür heißt “Jupyter”. Die Verwaltung der Rechenressourcen und Bibliotheken findet im Hintergrund durch Kaggle statt. Stark vereinfacht dargestellt, erstellt Kaggle eine funktionierende Programmierumgebung und dupliziert diese beliebig oft für jeden einzelnen Anwender*in.
Ein Nachteil der Verwendung von Kaggle ist, dass keine eigenen Datensätze hochgeladen werden können. Es wird lediglich ermöglicht, vorgefertigte Datensätze zu unterschiedlichsten Anwendungen zu bearbeiten. Glücklicherweise stellt Kaggle allerdings die vom Unternehmen ausgestaltete “Programmierumgebung” zum Download bereit. Mit der bereitgestellten Version lassen sich dann auch eigene Datensätze bearbeiten. Die Einbindung erfolgt hierbei mittels eines Docker-Containers. Einmal gestartet, kann entweder direkt lokal per Browser auf die Programmierumgebung zugegriffen werden oder Computer erreichen den Container über das lokale Netzwerk. Dieser Ansatz löst alle drei angeführten Problemstellungen auf:
| Ursprünglicher Nachteil | Lösungsansatz mittels Kaggle |
|---|---|
| – Das KI-Projekt liegt lokal ab und kann entsprechend nur von einer Person zur Zeit betreut werden. | – Aufgrund der Erreichbarkeit aus dem lokalen Netz kann auch gleichzeitig am Datensatz gearbeitet werden. |
| – Die Rechenleistung eines einzelnen Desktops ist in der Regel stark begrenzt. | – Die Installation auf einem Server ermöglicht die Bereitstellung deutlich größerer Rechenpower. Theoretisch ist auch die Installation auf On-Demand-Rechnern möglich. |
| – Die Kompatibilität der einzelnen Bibliotheken untereinander muss vom Anwender sichergestellt werden. Wird eine Bibliothek, zum Beispiel wegen einer neuen Funktion, aktualisiert, sollten auch alle weiteren verwendeten Bibliotheken aktualisiert werden. | – Da regelmäßig der gesamte Container seitens Kaggle aktualisiert wird, ist mit keinen Inkompatibilitäten zu rechnen. |
Entsprechend der vorgenannten Ausführungen hat auch die KI-Werkstatt auf eine Kaggle-basierte Lösung zurückgegriffen. Nachstehend sehen Sie eine Abbildung der Infrastruktur an der Leuphana Universität Lüneburg, wie sie im Rahmen des Projektes Anwendung gefunden hat:
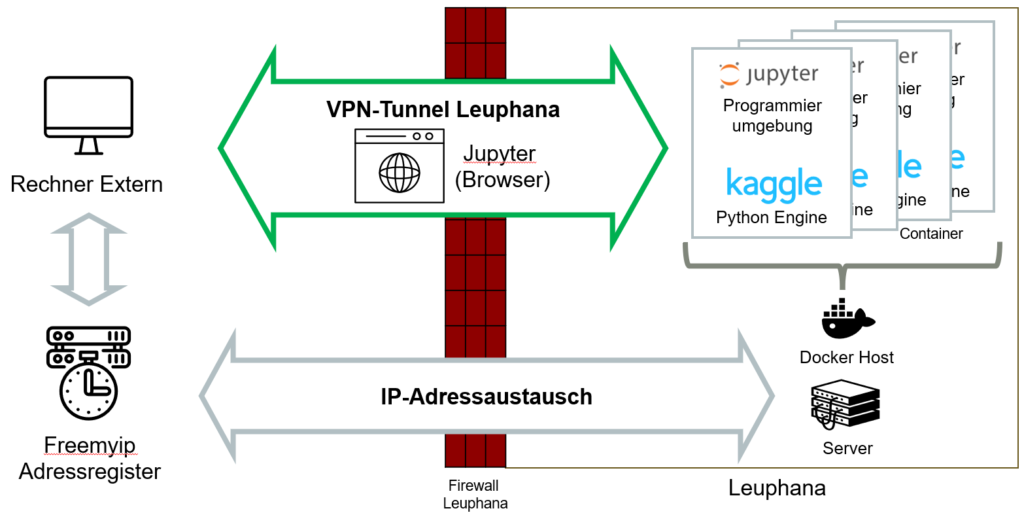
Auf der rechten Seite sehen Sie schwarz eingerahmt das interne Netzwerk der Leuphana, das mittels einer Firewall von der Außenwelt abgeschirmt ist. Die Verwendung des VPN-Tunnels ermöglicht die Arbeit mittels externen Rechnern im Intranet der Universität. Gleichzeitig teilt der im unteren Bereich abgebildete Server einem externen Dienst (“freemyip”) mit, welche IP-Adresse im internen Netzwerk gerade an den Server vergeben ist. Sollte die Vergabe von festen IP-Adressen, zum Beispiel in einem Unternehmensnetzwerk, möglich sein, kann dieser Schritt umgangen werden.
Im Netzwerk der Uni bildet ein Linux-basierter Server die Basis für die Bereitstellung der Docker-Container. Er stellt den sogenannten Docker-Host dar. Da im Rahmen der KI-Werkstatt unterschiedlichen Nutzern Zugriff auf unterschiedliche KI-Projekte gewährt wurde, wurde der Kaggle-Container hier gleich mehrfach parallel betrieben und mit Passwörter und Nutzeraccounts voneinander abgeschirmt. Die Verteilung der Rechenpower erfolgt hierbei lastorientiert.
Sollten Sie Fragen zum Aufbau einer Entwicklungsumgebung für KI-Projekte in Ihrem Unternehmen haben, kontaktieren Sie uns gerne.
Künstliche Intelligenz in Produktionsunternehmen.
Leuphana Universität Lüneburg
