Frachtpreisprognose
Im Folgenden soll anhand des Beispiels der Frachtpreisprognose bei einem Logistikunternehmen ein Projekt der KI-Werkstatt vorgestellt werden.
1) Preisfindung: Frachtpreis in der Logistik
Ausgangssituation
Ein Kooperationspartner der KI-Werkstatt war ein Logistikunternehmen für Recyclingprodukte. Das Unternehmen tritt gegenüber den Kunden als Entsorger auf. Die Kunden des Unternehmens zahlen dementsprechend für die Entsorgungsleistung. Das Unternehmen organisiert dann den Transport und die Verbringung des Abfalls bei entsprechenden Verwertern. Dafür sucht es auf dem Transportmarkt nach den besten Konditionen. Um kein Verlustgeschäft zu machen, ist es also schon bei der Angebotserstellung beim Kunden wichtig zu wissen, welcher Frachtpreis für die benötigte Lösung des Kunden auf dem Transportmarkt zu erwarten ist.
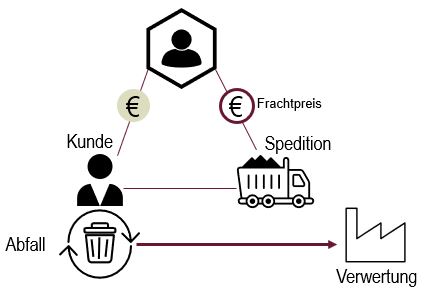
- Frachtpreismarkt sehr dynamisch
- regionale, produkt- und streckenbezogene Einflussfaktoren
- Präzise Preisbestimmung in der Vermakelung von hoher wirtschaftlicher Relevanz
- verhandelte Preise beruhen derzeit auf der jahrelangen Erfahrung der Geschäftsführung
Ziel:
Frachtpreisbestimmung durch Anwendung von Maschinellem Lernen
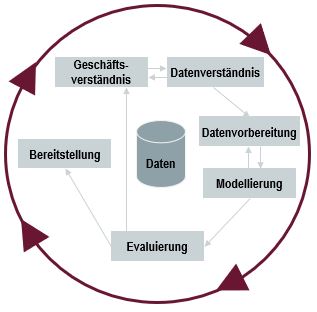
2) Cross Industry Standard Process for Data Mining (CRISP-DM)
Wie in jedem Projekt der KI-Werkstatt orientiert sich das Vorgehen am CRISP-DM. Zu jeder Phase werden im Folgenden wichtige Schritte im Projekt aufgezeigt. Das genaue Vorgehen im Rahmen des CRISP-DM finden Sie auf der Seite “Vorgehen im KI-Projekt“.
for Data Mining (CRISP-DM)
Datenverständnis
3) Sammlung von Anfangsdaten
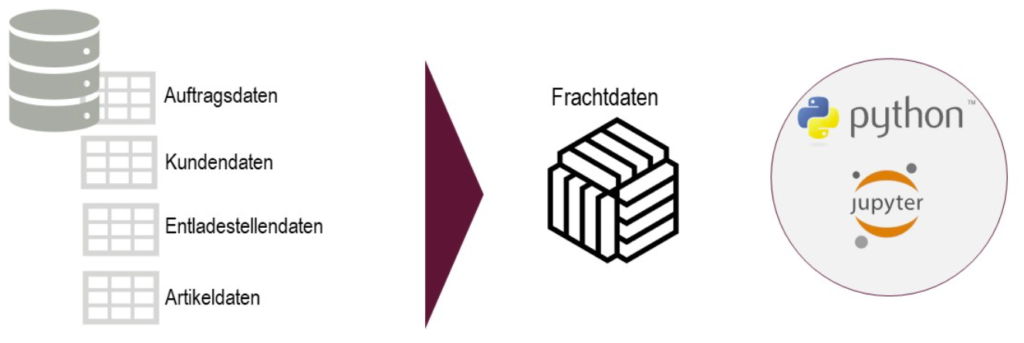
Frachtdaten werden aus SQL-Datenbank bezogen:
Jede KI-Anwendung basiert auf Daten, die im Zusammenhang mit der Fragestellung stehen. Bei der Sammlung der Daten sind zunächst alle möglicherweise relevanten Daten zu berücksichtigen. In unserem Beispielprojekt werden die Geschäftsdaten in einer SQL- Datenbank gespeichert. Für die Fragestellung wurden daraus vier wesentliche Tabellen extrahiert und miteinander verknüpft, sodass ein großer Datenwürfel mit den zu untersuchenden Frachtdaten entsteht. Die Zusammenführung und Analyse der Daten erfolgt in der Programmiersprache Python. Im Data Science Bereich haben sich zudem Jupyter Notebooks als Entwicklungsumgebung etabliert.
4) Beschreibung der Daten
Wichtige Merkmale der Daten
Die gesammelten Daten sind allgemein betrachtet eine Vielzahl von beschreibenden Elementen für einen Zusammenhang, auch Attribute genannt. Für ein Auto könnten die Attribute beispielsweise die Farbe, Marke, Modell, Baujahr, Preis, Kaufdatum, E-Auto (ja/nein) oder ähnliches sein.
Im Bereich des maschinellen Lernens wird eine Unterscheidung in das Zielattribut und beschreibende Attribute vorgenommen. Letztere lassen sich unterteilen in numerische und kategorische Attribute. Zusammenfassend stellen sich zu Beginn der Betrachtung der Daten folgende Fragen:
- Welches ist das Zielattribut, welches sind beschreibende Attribute?
- Von welcher Art ist das Attribut (numerisch, kategorisch)?
- Wie viele unterschiedliche Werte gibt es?
- Gibt es doppelte oder fehlerhafte Einträge?
- Sind die richtigen Datentypen zugewiesen?
- Wie ist die Statistische Verteilung der Werte (Mittelwert, Median, Standardabweichung, etc.)?
Datenbasis umfasst Attribute und den Vorhersagezielwert
Der Datensatz in unserem Beispielprojekt ist in der nachfolgenden Grafik zusammengefasst. Er umfasst insgesamt 22 Attribute. Dabei ist der Frachtpreis das Zielattribut (auch “Target”, gelb markiert). Alle anderen sind beschreibende Attribute (auch “Features”) und stehen jeweils in einem Verhältnis zum Frachtpreis. Wie sehr dieses Verhältnis ausgeprägt ist, gilt es in den nächsten Schritten herauszufinden. Stark ausgeprägte Beziehungen helfen später dem Algorithmus bei der Prognose.
Wir sehen zudem die Anzahl unterschiedlicher Werte und auch, dass in Spalten keine Werte enthalten sind (bei weniger als 14244 non-null values). Dies ist für jedes Attribut zu prüfen.
Da unser Zielattribut nur 13824 Werte enthält, ist es sinnvoll auch nur diese Einträge zu berücksichtigen. (es sei denn in Absprache mit dem Unternehmen können sinnvolle Annahmen bei fehlenden Werten getroffen werden)

5) Untersuchung der Daten
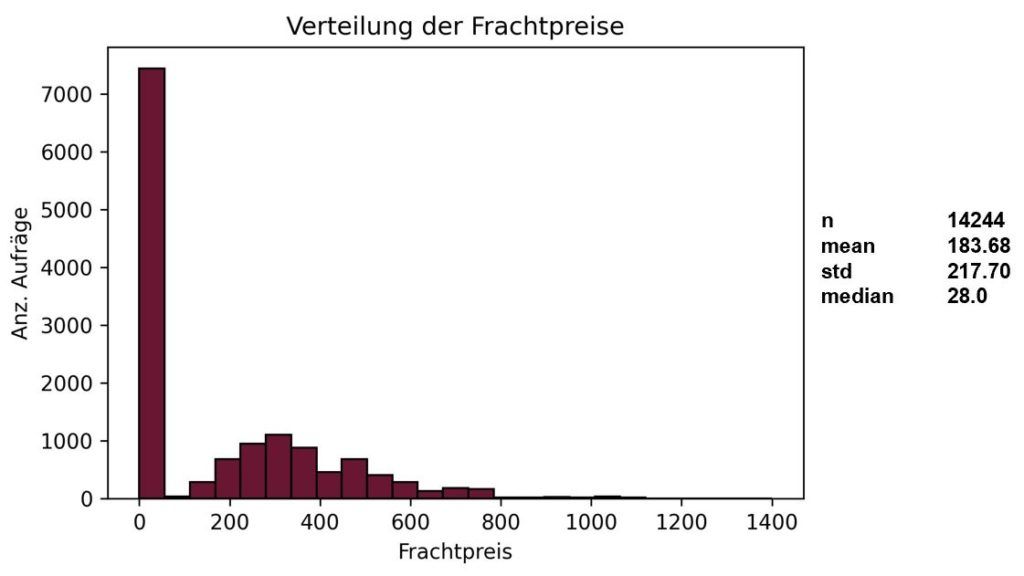
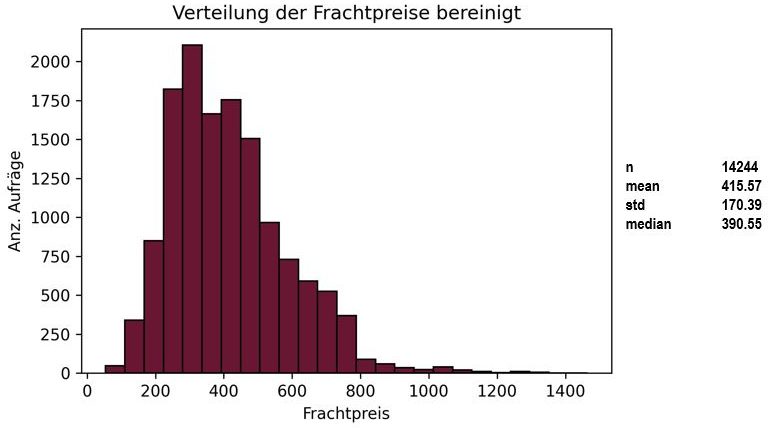
Vorhersagezielwert: Frachtpreis
Im nächsten Schritt gilt es die Daten zu untersuchen. Die Verteilung des Zielwerts und weitere statistische Kennwerte sind in der nachfolgenden Grafik dargestellt.
Die wichtigste Erkenntnis an dieser Stelle war, dass eine Vielzahl von Aufträgen mit Gesamtpreisen zwischen 0 € und weniger als 30 € liegen (Anzahl Aufträge/Frachtpreis). Daraus entstand folgender Klärungsbedarf:
- Was sind dies für Werte, sind diese ggf. trotzdem nutzbar?
- Wodurch könnten diese Werte ggf. nutzbar gemacht werden?
Die Antworten auf diese Fragen können nur im Dialog mit dem Unternehmen gefunden werden. Die Fehlerwerte bestehen zum einen aus fehlerhaft eingetragenen 0€ Aufträgen und Aufträgen, bei denen statt des Gesamtpreises ein Preis in €/Tonne geführt wird. Dies ist im Zuge der Datenvorbereitung zu bereinigen (siehe Punkt 8)).
6) Überprüfung der Datenqualität der beschreibenden Attribute
Ausprägungen im Attribut Fahrzeugart
Vor der Datenbereinigung gilt es jedoch auch die beschreibenden Attribute zu untersuchen.
In vielen Unternehmen sind Freitextfelder noch usus. Für Datenauswertungen und datenbasierte Entscheidungen wie bei ML ist dies ein Problem, da dadurch hohe Freiheitsgrade bei der Eingabe entstehen. Rechts dargestellt ist ein Beispielfeld aus dem Projekt. Es konnten viele unterschiedliche Einträge mit gleicher Aussage identifiziert werden, die sich nur mit großem Aufwand vereinheitlichen lassen.
Unternehmen sollten stets versuchen, Daten möglichst weit zu strukturieren, um Auswertbarkeit sicherzustellen.

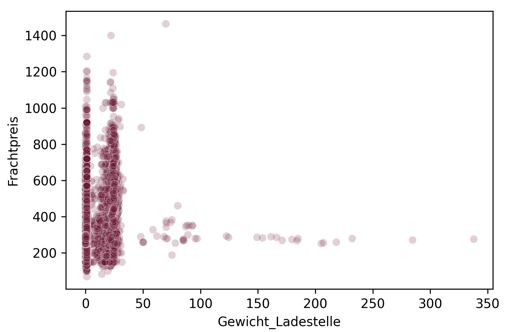
Ausprägung des Attributs Ladegewicht
Aber auch vermeintlich nützliche Attribute, wie etwa das Ladegewicht beim Transport, können nicht aussagekräftig sein. Dies lässt sich durch grafische Auswertungen untersuchen. Hier ist zum Beispiel ein Scatterplot hilfreich. (X-Achse: Ladegewicht, y-Achse: Frachtpreis, jeder Punkt = ein Auftrag). Aus der Grafik ist zu erkennen, dass viele Punkte bei 0 kg Gewicht, bei unterschiedlichen Frachtpreisen angesiedelt sind. Zudem ist eine starke Streuung hinsichtlich des Frachtpreises erkennbar, mit einigen fehlerhaften Werten mit unzulässigen Ladegewichten von weit mehr als 30-40 tonnen.
Es ist somit keine aussagekräftige Beziehung zum Frachtpreis erkennbar.
7) Datenauswahl
Der Datensatz beinhaltet bereits viele Informationen (Siehe Punkt 4). Allerdings könnten noch weitere Informationen relevant sein. Ausgehend vom Geschäfts und Prozesswissen des Unternehmens konnten weitere relevante Informationen identifiziert werden (siehe unten). Wie sich diese in den Datensatz integrieren lassen, sehen wir im Zuge der Datenvorbereitung.
Was ist vorhanden?
- Kunde
- Spediteur
- Artikel
- Datum
- Gewicht
- Ortsdaten Kunde
- Ortsdaten Entladestelle
Welche Informationen könnten noch relevant sein?
- Distanz und Dauer der Fahrt
- Kraftstoffpreis am Markt
- Fahrtrichtung (Regionen)
- Verfügbare Kapazität am Markt
- Höhenprofil
Datenvorbereitung
8) Bereinigung der Daten
Ersetzen fehlerhafter Werte
Im Folgenden wird gezeigt, wie wir zusätzliche Informationen in den bestehenden und aus externen Attributen genutzt haben.
Zu Beginn jedoch noch einmal zurück zu dem ungleich verteilten Zielattribut. Zunächst wurden in €/to angegebene Preise mit dem Ladegewicht multipliziert. Für 0€-Aufträge bekamen wir vom Unternehmen die Freigabe simple Annahmen zu treffen:
- Unter 200 km wird ein Fixpreis zwischen 250-350€ zugewiesen
- Über 200 km wird ein km-Preis von 1,40€ – 1,50€ pro km angenommen.
Um diese Annahmen umzusetzen, ist jedoch erforderlich die Distanz als weiteres Attribut in den Datensatz zu integrieren. Zudem muss die auf dem Transportmarkt übliche Kalkulation anhand des Frachtpreises je km in den Datensatz übertragen werden. Das eigentliche Zielattribut ist somit gar nicht im Datensatz enthalten, sondern muss erst durch Hinzufügen der Distanzinformation zum Datensatz gebildet werden (siehe Punkt 9). Die Umsetzung der Annahmen führt zu einer deutlich harmonischeren Verteilung der Frachtpreise (siehe Abbildung).
9) Integration externer Attribute
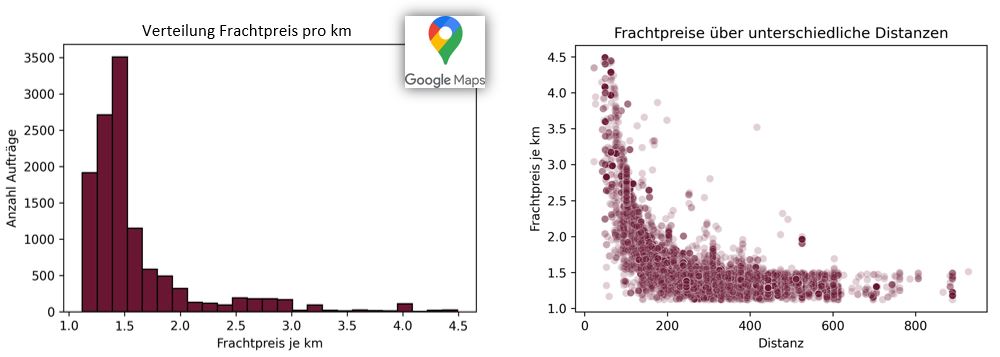
Distanz und Dauer über Kartenanbindung
Um den Frachtpreis pro km zu berechnen, fehlt das Attribut Distanz in der Datenbank vom Projektpartner. Jede Fracht einzeln bei Maps eingeben, ist keine Option, weder für die bestehenden Daten, noch für eine zukünftige Anwendung. Es kann allerdings eine bestehende GoogleMaps Schnittstelle genutzt werden. Mit ein wenig Programmcode können über die verfügbaren PLZ und Orte die Distanzen und Fahrtdauern aller Aufträge ermittelt und in den Datensatz eingespeist werden. Dies ist ein erstes Beispiel dafür, wie auch unternehmensexterne Daten für KI-Anwendungen genutzt werden können.
Es ist ein klarer Zusammenhang zwischen der Verteilung der Frachtpreise/km und den Aufträgen aufgeteilt nach Distanz und ihrem Frachtpreis zu erkennen.
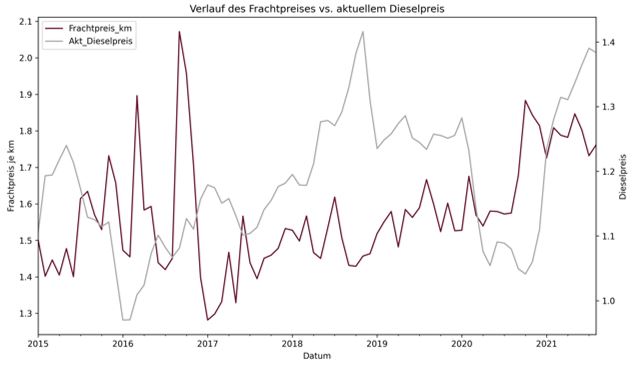
Integration des aktuellen Dieselpreises über API
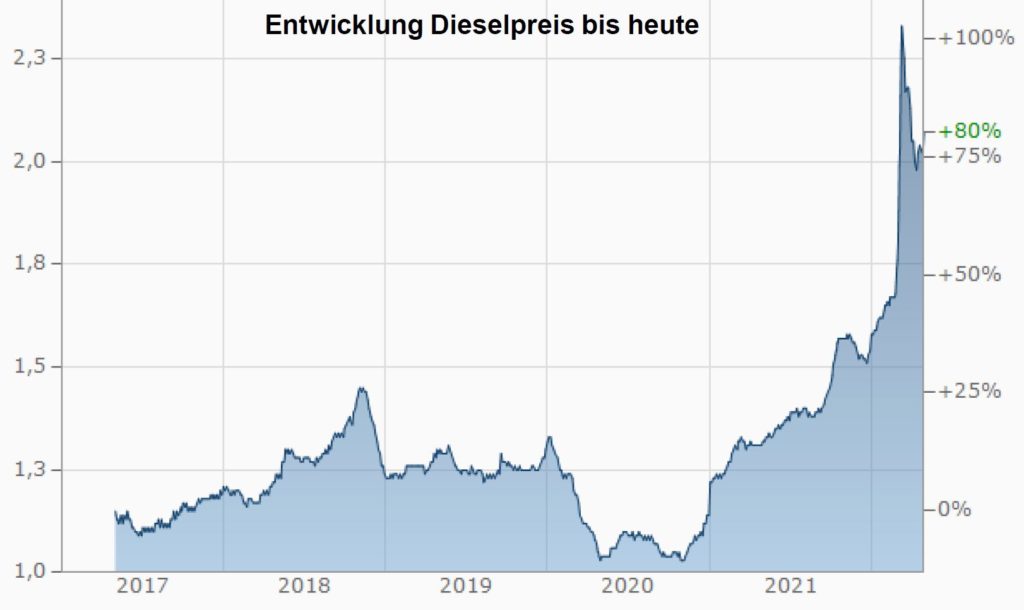
Als weiteres neues Attribut bietet sich im Transportwesen der Dieselpreis an. Ein grafischer Vergleich des durchschnittlichen Frachtpreises/km (rot) mit dem Dieselpreis (grau) unterstreicht die Beziehung. Insbesondere ab 2017 schwanken die Werte in der Tendenz miteinander. Eine Integration erscheint damit sinnvoll und kann ebenfalls über eine automatische Schnittstelle umgesetzt werden.
Entwicklung des Dieselpreises ab Ende 2021
Allerdings sind marktbasierte Attribute mit Vorsicht zu genießen. Da das Modell im Jahr 2021 entwickelt wurde, verwendet das Modell eine Zeitreihe mit moderater Dieselpreisentwicklung (siehe Entwicklung bis Mitte 2021). Gerade die jüngste Entwicklung des Dieselpreises ist eine Herausforderung für das Modell. Die extremen Preise aus 2022 werden demnach nicht durch das Modell berücksichtigt. Es zeigt sich somit, dass der Dieselpreis heute noch eine größere Bedeutung hat, diese jedoch vom Modelldatensatz nicht abgebildet wird.
10) Abwandlung von Attributen
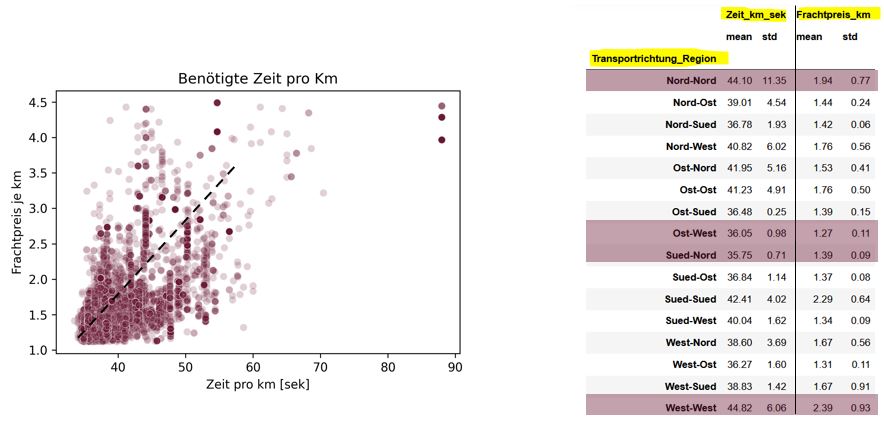
Durchschnittsgeschwindigkeit und Richtung
Weiterhin ist interessant, von wo nach wo der Transport stattfindet und ob dieser Weg über Autobahnen oder Landstraßen, oder durch Stadtgebiet oder Nadelöre mit Staupotenzial führt. Aus den Google-Daten lässt sich neben der Distanz auch die Dauer ableiten, woraus die benötigte Zeit je km berechnet werden kann, also ein Indikator für die Durchschnittsgeschwindigkeit. Die Grafik links zeigt den Frachtpreis je km in Abhängigkeit von der Zeit je km. In der Tendenz steigt der Frachtpreis, je länger man für einen km braucht. Die Transportrichtung scheint hier ein entscheidender Faktor zu sein (Tabelle rechts). Beispielsweise ist die Zeit/km auf der Kurzstrecke im Norden und Westen am höchsten. Während die längeren Strecken Süd-Nord und Ost-West die geringsten Werte aufweisen. Dies schlägt sich auch im Frachtpreis/km nieder. Genau diese Varianz ist ein idealer Anknüpfungspunkt für die KI.
11) Kreation neuer Attribute
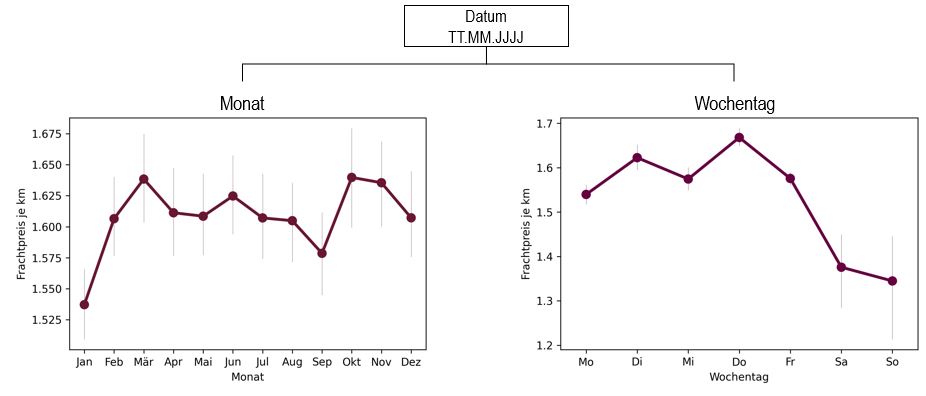
Nutzung von Datumsfeldern zur Analyse
Aus Datumsfeldern in dem Datensatz, können Schwankungen des Frachtpreises unter der Woche oder im Jahresverlauf ermittelt werden.
Wie man sieht kommt es im Laufe des Jahres zum Teil zu deutlichen Unterschieden. Auffällig sind die Vorweihnachtszeit und sowie die abnehmende Tendenz in den Sommermonaten. Auch innerhalb einer Woche zeigen sich deutliche Schwankungen. Am Donnerstag erreicht die Frachtrate ihren Höhepunkt. Zum Wochenende sinkt der Frachtpreis/km ab. Genau nach solchen Varianzen sucht der Algorithmus, um bei zukünftigen Aufträgen die Prognose mit der richtigen Tendenz einzuordnen. Monat und Wochentag sind also neue Attribute, die wir in das Modell einfließen lassen können.
12) Zusammenfassung Datenauswahl
Datenauswahl als iterativer Prozess
Zusammenfassend kann also gesagt werden, dass der Datenauswahlprozess ein iterativer Prozess ist, der die Integration neuer, aber auch das Verwerfen und Abwandeln alter Attribute beinhaltet. Wir haben gesehen, dass wir neue Attribute aus bestehenden kreieren können.
Hier sind die Unternehmer die besten Experten für mögliche potenziell, relevante Informationen. Der Haken ist jedoch, dass externe Informationen nicht immer umsonst sind, was es letztlich abzuwägen gilt.
Genauso sollten Attribute entfernt werden, die nicht interpretierbar sind und das Modell verwirren. Außerdem zeigen Studien, dass einige Modelle mit steigendem irrelevanten Informationsgehalt zunehmend schlechter werden.
Für das Beispielprojekt haben wir in der Datenvorbereitung aus dem Anfangsdatensatz mit 22 Attributen einen Modelldatensatz mit insgesamt 25 Attributen entwickelt:

Hinzufügen von Daten
- Kreation neuer Attribute (z.B. Wochentag, Transportrichtung)
- Abwandlung von Attributen (z.B. Zeit pro km, Abfalltypen)
- Hinzufügen neuer, externer Attribute (z.B. Distanz, Dieselpreis)
Entfernen von Attributen
- Ausschließen von Attributen anhand der Analyseergebnisse:
- Ohne Einfluss auf Frachtpreisveränderung
- Doppelte/redundante Attribute
- Zu viele fehlende Werte
Modellierung
13) Vorbereitung Modellierung
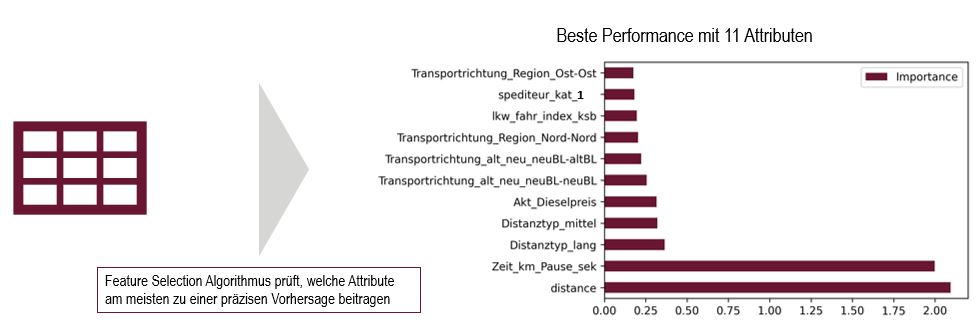
Feature Selection Prozess
Mit dem Modelldatensatz geht es nun in die Modellierungsphase. Anhand der Erkenntnisse der vorherigen Phasen sind 25 potenziell relevante Attribute zur Prognose des Frachtpreises/km manuell ausgewählt worden. Kategorische Attribute werden im Rahmen der Modellierung jedoch noch umgewandelt in lesbare Daten für Maschinen. Beispielsweise entstehen beim sogenannten Encoding aus einer Spalte mit fünf Farben (orange, rot, grün, blau, weiß) für die Modellierung fünf neue Spalten, in denen eine 1 steht, falls zutreffend. So entstehen extrem viele neue Attribute, die die Prognose “stören”.
Aus diesem Grund ist es ratsam, nach dem manuellen Prozess noch einen automatischen Prozess zur Feature Selection, also der Attributauswahl, anzuschließen. Im Beispielprojekt hat sich gezeigt, dass das Modell bei Auswahl von 11 Attributen am besten prognostiziert. Die Attribute werden geprüft, inwiefern sie zu einer präziseren Vorhersage beitragen oder nicht. Gemessen wird dies anhand der sogenannten Feature Importance. Rechts ist dargestellt, welche Attribute dem Modell am meisten helfen.
14) Modellierung: KI-basierte Prognose
Prinzip einer Regression mit Maschinellem Lernen
Beim Supervised Learning wird das Modell mit Trainingsdaten trainiert. Dies ist, vereinfacht dargestellt, eine große Tabelle in denen alle Aufträge stehen mit ihren Attributen. Gleichzeitig erhält das Modell die dazugehörigen Frachtpreise und lernt die Zusammenhänge in extrem hoher Geschwindigkeit. Der Lernprozess verläuft bei jedem Algortihmus anders und kann durch Parameter eingestellt werden. Der entstandene Algorithmus wird nun mit den Testdaten, also Frachtdaten ohne die dazugehörigen Frachtpreise, konfrontiert. Durch den Lernprozess mit den Trainingsdaten kann das Modell dann eine Prognose erstellen, die gegen die wahren Frachtpreise der Testdaten abgeglichen wird. Im Idealfall liegen die Punkte aus Prognose und korrekten Werten alle auf einer Geraden (siehe Grafik rechts). Die Performance wird durch den durchschnittlichen Abstand der Punkte zur idealen Gerade gemessen.
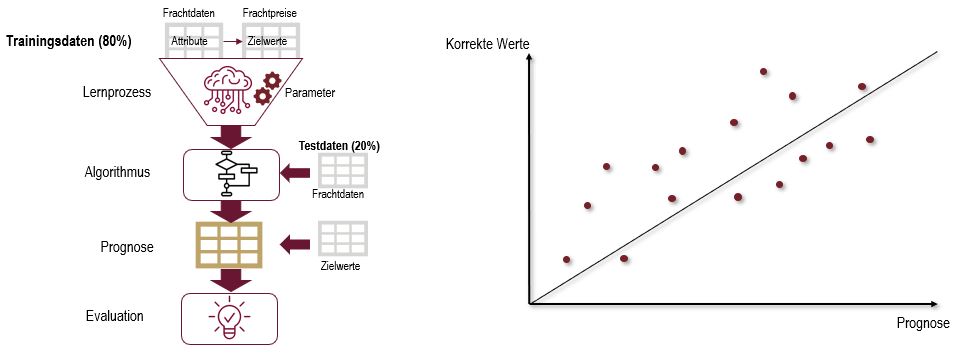
Es wurden insgesamt fünf verschiedene Supervised Learning Algorithmen getestet. Darunter sind einfache, leicht interpretierbare Modelle wie die Lineare Regression oder der Entscheidungsbaum (Decision Tree) und komplexere “Black-Box”-Modelle, die jedoch potenziell bessere Prognosefähigkeiten mitsichbringen. Folgende Algorithmen wurden getestet:
- Linear Regression
- Decision Tree
- Random Forest
- Gradient Boosting
- Xtreme Gradient Boosting
15) Benchmark
Vergleichsmodell zur Einordnung der Performance der ML-Modelle
Zum Abgleich der Performance der ML-Modelle mit dem aktuellen Vorgehen wurde dieses in Form einer Excel-Benchmark Prognose simuliert. Hierzu wurde das wichtigste Attribut ‘Distanz’ genutzt und Durchschnittswerte für Kurz-, Mittel-, und Langstrecken gebildet. Diese wurden auf das Testdatenset angewendet und, wie für die ML-Modelle, ein durchschnittlicher Fehler bestimmt. Folgendes sind die zugrundeliegenden Annahmen:
- Kurzstrecke (< 150 km) 2.47 €/km (2108 Fahrten)
- Mittelstrecke (150 – 400km) 1.45 €/km (7033 Fahrten)
- Langstrecke (> 400km) 1.32 €/km (2446 Fahrten)
Evaluation
16) Auswertung der KI-basierten Prognose
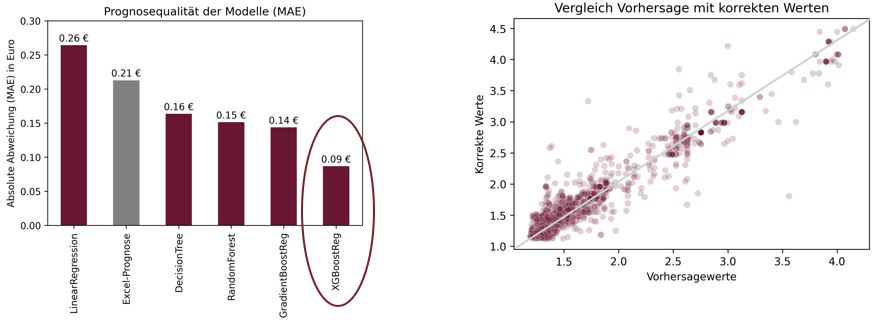
KI-Modelle können Fehler aus Benchmark um 25 – 60 % reduzieren
Abschließend lassen sich alle Modelle anhand einer Metrik wie z.B. den durchschnittlichen absoluten Fehler (Mean Absolute Error (MAE)) miteinander vergleichen. Es ist zu sehen, dass die Excel-Benchmark Prognose eine mittlere Abweichung von 21 Cent schafft. Die einfache lineare Regression liegt darüber.
Die komplexeren Algorithmen, aber auch der Entscheidungsbaum, die auch nicht lineare Zusammenhänge identifizieren können, reduzieren den Fehler jedoch deutlich. Der beste Algorithmus XGBoost kann den Fehler bis auf 9 Cent Abweichung reduzieren. Das sind ca. 60% Einsparungen für die Firma.
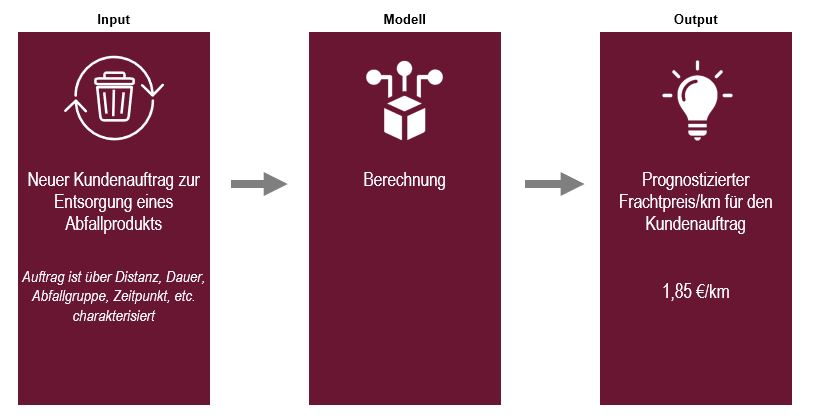
18) Implikationen für den Geschäftsprozess
Aufgrund der hohen Genauigkeit der Prognose ist eine Implementierung in das laufende Geschäft denkbar. Das trainierte Modell kann gespeichert und bei Bedarf mit neuen Auftragsdaten angefragt werden. Für diese Daten wird dann eine Prognose des Frachtpreises je km erstellt, die dann etwa in Form eines Entscheidungsvorschlags im laufenden System der Anwendenden erscheint. Der Ablauf ist abschließend schematisch dargestellt.
19) Deployment
Den Abschluss eines jeden KI-Projektes bildet das Deployment. In dieser Phase werden die Modelle auf die relevantesten Codebausteine reduziert und das fertig trainierte Modell in den alltäglichen Einsatz transferiert. Im vorgestellten beispiel wurde hierbei die KI direkt in die Access-basierte Frachtenplanung des Unternehmens implementiert. Das nachstehende Video zeigt das Tool im Einsatz.
Kontakt

Thorben Green, M.Sc.
Wiss. Mitarbeiter
Leuphana Universität Lüneburg
21335 Lüneburg, Universitätsallee 1, C12.212
Fon +49.4131.677-1751
thorben.green@leuphana.de
Künstliche Intelligenz in Produktionsunternehmen.
Leuphana Universität Lüneburg
